
Robots.txt – это текстовый файл, который размещается на веб-сайте и предназначен для управления активностью веб-пауков – программ, которые обходят сайты, чтобы индексировать их содержимое.
Индексные файлы – это инструмент, позволяющий веб-мастерам контролировать поведение веб-пауков на их сайтах. Они используются для указания, какие страницы сайта следует индексировать, а какие – нет. Важно отметить, что robots.txt не может защитить информацию от попадания в индекс поисковых систем, но он способен контролировать поведение пауков.
В robots.txt содержатся указания для веб-пауков относительно того, какие URL-адреса сайта им разрешено посещать, а какие – нет. Он также может быть использован для контроля скорости доступа к сайту, чтобы избежать перегрузки сервера и сократить время обхода. Этот файл позволяет веб-мастерам гибко настраивать индексирование, блокировать конкретные пути, запрещать роботам определенные действия и делать многое другое.
Что такое robots.txt и зачем нужен индексный файл
Robots.txt файл позволяет веб-мастерам определить, какие страницы сайта не должны быть сканированы или индексированы роботами поисковых систем. Он используется для запрета доступа к определенным директориям или файлам, а также для указания приоритетов сканирования различных разделов сайта. Благодаря robots.txt можно предотвратить индексацию временных или приватных страниц, а также защитить конфиденциальную информацию.
Индексный файл можно создать и редактировать вручную или автоматически с помощью специальных программ. Он должен быть размещен в корневом каталоге сервера сайта и иметь название «robots.txt». Файл записывается на специфическом языке, который основан на синтаксисе похожем на язык программирования.
Правильное использование robots.txt файла помогает поисковым системам более эффективно сканировать сайт, не тратья ресурсы на неинтересующие и несущественные страницы. Однако неправильная или нежелательная конфигурация robots.txt файла может привести к проблемам с индексацией и видимости сайта в поисковых результатах.
Зачем нужен robots.txt
Robots.txt позволяет веб-мастерам контролировать доступность своих страниц для поисковиков. Он используется для ограничения индексации определенных разделов сайта, таких как административные панели или частные страницы, которые не должны отображаться в результатах поиска.
Основная цель robots.txt — сократить нагрузку на сервер, не допуская излишней индексации ненужных страниц. Если поисковик не может найти файл robots.txt на сайте, он будет пытаться проиндексировать все страницы сайта, что может вызвать перегрузку сервера и замедлить работу сайта.
Кроме того, robots.txt может использоваться для блокировки доступа поисковикам к разделам сайта, содержащим конфиденциальную информацию или которые пока еще не готовы к публикации.
Однако важно помнить, что robots.txt не предоставляет полную защиту от индексации страниц. Некоторые роботы могут проигнорировать инструкции в файле или даже найти скрытые страницы, если есть ссылки на них с других источников.
Структура файла robots.txt
Структура файла robots.txt включает в себя набор правил, представленных в виде команд, которые поисковый робот должен прочитать и выполнить. Каждая команда начинается с указания раздела User-agent, где указывается идентификатор робота, к которому относится данная команда, и после двоеточия следует описание правила.
- User-agent: определяет, к какому роботу или группе роботов относится следующее правило. Возможным значением является символ «*» — это означает команду, которая будет действовать на всех роботов.
- Disallow: указывает директорию или файл, доступ к которым запрещен для роботов. Запись «Disallow: /» означает, что доступ ко всем разделам сайта запрещен.
- Allow: указывает директорию или файл, доступ к которым разрешен для роботов. Однако, данный параметр не поддерживается всеми роботами.
- Sitemap: указывает путь к файлу sitemap.xml, который содержит информацию о карте сайта.
Одним из преимуществ использования файла robots.txt является возможность ограничить доступ роботам к определенным разделам сайта, что позволяет сконцентрировать их индексацию на важных страницах, улучшая таким образом процесс индексации и повышая общую видимость веб-ресурса в поисковых результатах.
Примеры использования robots.txt
Рассмотрим несколько примеров использования robots.txt:
1. Запрет на индексацию всего сайта
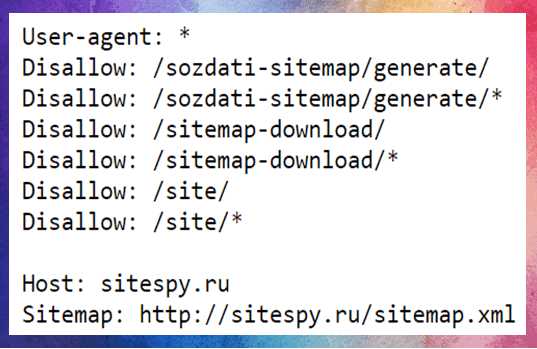
Если вы хотите запретить поисковым роботам индексировать весь ваш сайт, вы можете использовать следующую запись в файле robots.txt:
User-agent: *
Disallow: /
Эта запись указывает на то, что все роботы должны воздержаться от индексации любой страницы сайта, начиная с корневой директории.
2. Запрет на индексацию конкретных страниц
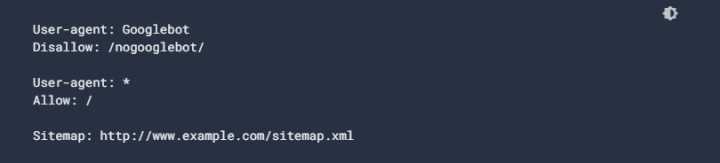
Если вам необходимо запретить индексацию конкретных страниц, вы можете указать их пути в соответствующей записи. Например:
User-agent: *
Disallow: /private-page.html
В данном случае роботам буде запрещено индексировать страницу с путём /private-page.html.
3. Запрет на индексацию определенного типа файлов
Если вы не хотите, чтобы роботы индексировали файлы определенного типа, вы можете указать его расширение в записи. Например:
User-agent: *
Disallow: /*.pdf$
В данном случае все роботы будут отказано в доступе к любым файлам с расширением .pdf.
Итог
Файл robots.txt является индексным файлом, который позволяет вам контролировать доступ поисковых роботов к содержимому вашего сайта. Правильное использование robots.txt помогает оптимизировать индексацию, защищает конфиденциальную информацию и позволяет управлять трафиком сайта. Заполнение robots.txt требует некоторых знаний и понимания работы поисковых роботов, но может значительно улучшить оптимизацию сайта для поисковых систем.
Наши партнеры: